BACKGROUND
Government communications are notoriously hard to read. Agencies publish a lot of content online, and most of it is written for bureaucrats, not citizens. BC Parks, like many public sector organizations, has a web writing guide to address this, with rules around plain language, sentence length, and active voice. The problem isn’t awareness. Research on public sector writing finds that non-compliance usually comes down to two things: writers don’t know the guidelines well enough, or they don’t have time to apply them consistently. A communications officer publishing a park advisory is juggling it alongside a dozen other tasks, with no real-time feedback on whether what they’ve written meets the standard.
HYPOTHESIS
An AI writing assistant could close that gap. If we gave a language model the writing guidelines and asked it to check content against them, we could give writers real-time, specific feedback without adding a review bottleneck. The question was whether we could make that feedback reliable and accurate enough to actually trust.
APPROACH
Over the course of a hackathon, we built a web-based tool that accepts a block of government web copy and returns two things: inline annotations on specific problem sentences, and a plain-language summary score using the Hemingway readability method. The guidelines we checked against came directly from the BC Parks web writing guide, with five rules hard-coded into the system.
Under the hood, we made two separate calls to GPT-5.1. The first pass generated inline feedback, flagging which sentences violated which rules. The second pass produced the overall summary and score. Each call used a prompt template that injected the user’s text and the relevant guidelines dynamically:
prompt_template = f"""
You are an internal policy compliance auditor for an organization.
## Guidelines to check against
{guidelines_text}
## Content to evaluate
{user_text}
"""We used Pydantic to enforce a strict JSON output schema so responses were always structured the same way, and set temperature=0.0 to keep output deterministic:
response = client.beta.chat.completions.parse(
model="gpt-5.1-2025-11-13",
messages=messages,
response_format=UnifiedGuidelinesLLMResponse,
temperature=0.0
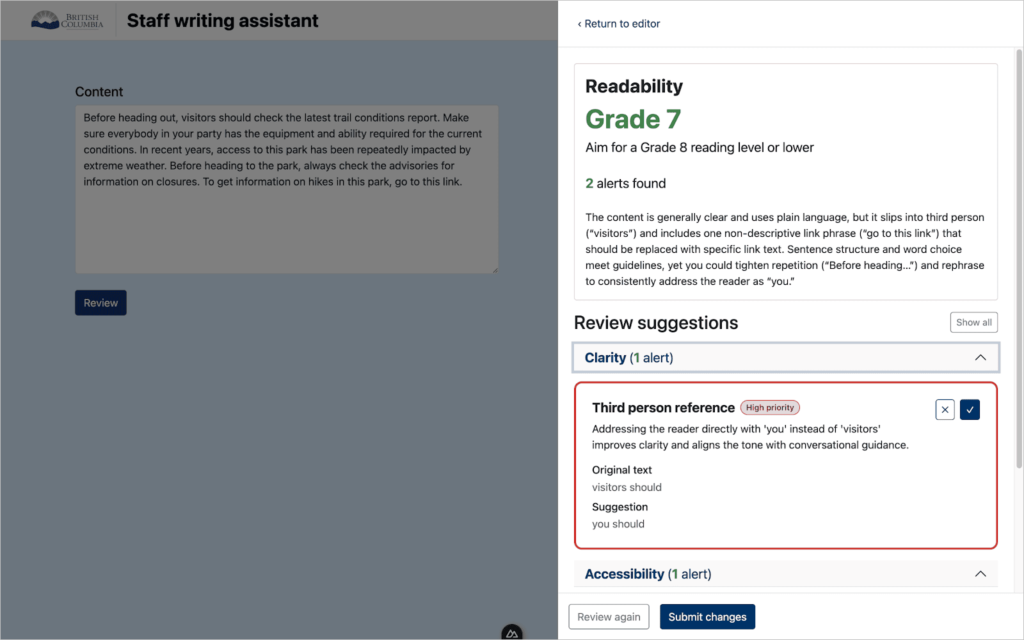
)The more interesting problems were in the prompt logic. When a sentence broke multiple rules, the model would return separate suggestions for each violation. Take this example: Visitors must utilize the designated camping areas. Without the right constraints, the model returned two separate fixes: one flagging “Visitors” as third-person, another flagging “utilize” as bureaucratic language. Both correct, but if a writer accepts the first suggestion, the second now points to text that no longer exists. We fixed this by adding an explicit no-duplicate-coverage rule: each piece of text can appear in at most one feedback item, and when multiple guidelines apply, the model combines them into a single suggestion.
Position accuracy was the other tricky one. The model was bad at calculating character offsets, which matters when you’re highlighting a specific span in an editor. It got worse when the same word appeared more than once in a document. For a sentence like The visitor must ensure their passes are visible, the model might correctly identify “The visitor” as the text to replace with “You”, but return the wrong character position, pointing to a different part of the document entirely. Our solution was to stop asking it to count characters at all. Instead, we asked the model to return the flagged text plus a few words of surrounding context, then used a plain string processor to find the exact position. The model finds what’s wrong; the code finds where it is.
TAKEAWAYS
01
Telling an AI what to look for matters more than which AI you use. The model had opinions about government writing even before we gave it the guidelines. Without clear instructions to check only against our specified rules, it would add its own suggestions. Getting precise feedback meant being precise about scope, and that’s a prompt engineering problem, not a model selection problem.
02
Position accuracy is something you have to build around, not rely on the model for. AI models are bad at counting characters and calculating offsets in text. We learned this the hard way when the same phrase appeared multiple times in a document and the model pointed to the wrong one. The fix was to treat position-finding as a separate step using conventional string processing. The model finds what’s wrong; the code finds where it is.
03
Evaluating one thing at a time beats evaluating everything at once. When we asked the model to check all five guidelines in a single prompt, accuracy dropped. When we ran one guideline per call and combined the results, we got cleaner, more consistent output. This adds latency, but for a writing tool where users can wait a couple of seconds, it’s worth it. The lesson generalizes: AI systems that try to do too much in one shot often do all of it worse.
04
The most interesting product question wasn’t technical. Should the tool flag things that are genuinely bad writing but not explicitly covered by the guidelines? We built it to stay in its lane, but a real product owner would need to decide that. The answer probably depends on how much the writers trust the tool. Too many suggestions and they’ll ignore all of them.
DEPLOYMENT IN A GOVERNMENT CONTEXT
This experiment used OpenAI’s standard API, which is appropriate for a hackathon but not for production government content. A real deployment would point the tool at an approved enterprise LLM endpoint. In BC, that means BC’s Microsoft Enterprise Copilot environment. Because the tool is designed to work against any LLM API, that swap is a configuration change, not a rebuild.
Beyond the endpoint, a production version would need several additional controls in place. Content submitted for review should never be logged or retained by the LLM provider. Requests should be routed through a government-controlled proxy so that no draft text leaves the approved environment. Role-based access would limit who can submit content and which guidelines they check against. All API calls should be audited and logged on the government side for accountability. If the tool is embedded in an existing CMS, it should inherit whatever authentication and session management that system already has rather than introducing its own.
CODE
Want to try it yourself? The full source code is on GitHub.